Generalized Nonaveraging Integer Sequences January 9, 2015
Posted by Dennis in Uncategorized.trackback
Everybody who participated in RSI 2009 from this blog have now just finished their undergraduate degrees. I think it’d be interesting to have an update to see how everybody is doing.
I think in the future, I’ll add posts here either to 1) explain intuitively what happens in a paper of mine or 2) write the proof or idea of something that is hard for me to find in the literature. The audience for 1) is going to be really small, considering the lack of papers and people who read them (but I feel sorry for them), and 2) would be to help myself learn.
This time, I’ll try to outline intuitively what went on in my RSI project 5 years ago, the reason being that the main ideas (I think) are pretty well-disguised behind the technical details, which are really just a bunch of casework. The paper is here: http://arxiv.org/pdf/1107.1756.pdf.
As for motivation, we recall that there is the open problem of trying to find the largest subset 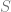
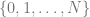

Disregarding the current literature, the most naive way to approach this problem is to use the greedy algorithm. Namely, you start with
It turns out that the greedy algorithm generates a sequence 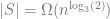
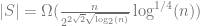
The condition that the sequence has no three term arithmetic progression is equivalent to avoiding (nontrivial) solutions to 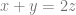
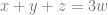
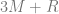
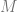
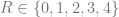
What happens if we consider avoiding solutions to
where all the 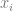
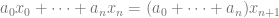
In general, I think we don’t understand this at all (or at least we didn’t understand it 5 years ago). From generating these sequences with a computer, it seems like, if you have a bunch of terms that are close together, then that forces the next terms in the sequence to be farther apart. Similarly, if a bunch of terms are far apart, then the next terms in the sequence are closed together. This makes complete sense heuristically.
I wish I still had the actual graphs to give an idea, but the graph of the sequence would typically be flat at the beginning, suddenly grow because of the terms bunched together. Then, since the terms are spread out, it would suddenly become flat again. This would repeat. Instead of simply cycling, the times where the graph is either flat or growing really fast increases with each iteration. I think they increase geometrically, but it was hard to compute enough terms to see.
In some very special cases, this pattern is so extreme that the part where the graph is growing really fast is instead a perfect jump. This is because the terms in the beginning are so bunched together that there are simply no gaps to stick any more terms. Consider, for example, the graph of the sequence that avoids 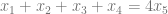

My RSI paper was just to try to find these some of these sequences and their closed forms (for example the one above). The idea is the same as Layman’s paper, where the closed form is 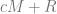

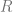
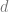
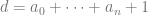
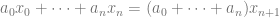
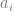
In general, I think it’s interesting to try to find the growth rate of these sequences, but my guess is that it is difficult. In fact, I didn’t found anything in the literature that beats the silly counting argument (other than heuristic arguments) during RSI in terms of an upper bound. It’s messy, yet not random.

Hi, beast, is this your blog? I got here via a link on Terry Tao’s blog.
郑大师, Akhil Mathew started this blog during RSI 2009, and he invited the other students who were doing something math-oriented to the blog in hopes of having a group blog.
Most of the content in the year or two after was from Akhil (with maybe a fraction coming from the rest of us combined). He has since then moved to https://amathew.wordpress.com/, and I think nobody has posted for 4 years before this post.
So it’s not really my blog…I can’t even edit my biography on the about page because my account doesn’t have the privileges to do that. I’m hoping that other people who were a part of this might consider posting cooler stuff.