Extensions of Line Bundles on the Projective Line January 26, 2015
Posted by Dennis in algebraic geometry.add a comment
The following is probably obvious to experts, as it is easy to find generalizations using google. However, this humble master’s student didn’t find this most basic case, so it’s probably worth writing down.
We will be working over the projective line 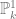

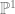
For example, given that we we know 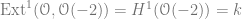
 .
.Recall that all vector bundles over 
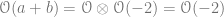
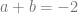

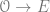

One way to produce an example of such a nontrivial extension is from the Koszul complex. Recall that the complex
![0\rightarrow k[x,y]\xrightarrow{\begin{pmatrix} -y\\x \end{pmatrix}}k[x,y]\oplus k[x,y]\xrightarrow{\begin{pmatrix} x & y\end{pmatrix}}k[x,y]\rightarrow k\rightarrow 0](https://s0.wp.com/latex.php?latex=0%5Crightarrow+k%5Bx%2Cy%5D%5Cxrightarrow%7B%5Cbegin%7Bpmatrix%7D+-y%5C%5Cx+%5Cend%7Bpmatrix%7D%7Dk%5Bx%2Cy%5D%5Coplus+k%5Bx%2Cy%5D%5Cxrightarrow%7B%5Cbegin%7Bpmatrix%7D+x+%26+y%5Cend%7Bpmatrix%7D%7Dk%5Bx%2Cy%5D%5Crightarrow+k%5Crightarrow+0&bg=ffffff&fg=666666&s=0&c=20201002)
is exact. Turning this into sheaves over
 .
.Notice that this only works because 
![k[x,y]](https://s0.wp.com/latex.php?latex=k%5Bx%2Cy%5D&bg=ffffff&fg=666666&s=0&c=20201002)
Repeating the argument above, we see that any extension
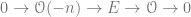 .
.must have 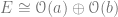


________________________________________________________________________________________________
Edit: Sometime after posting this, I realized there was a way to get these extensions in exactly the same way as above with the Koszul complex. Namely, we take the exact sequence
![0\rightarrow k[x,y]\xrightarrow{\begin{pmatrix} -y^j\\x^i \end{pmatrix}}k[x,y]\oplus k[x,y]](https://s0.wp.com/latex.php?latex=0%5Crightarrow+k%5Bx%2Cy%5D%5Cxrightarrow%7B%5Cbegin%7Bpmatrix%7D+-y%5Ej%5C%5Cx%5Ei+%5Cend%7Bpmatrix%7D%7Dk%5Bx%2Cy%5D%5Coplus+k%5Bx%2Cy%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\xrightarrow{\begin{pmatrix} x^i & y^j\end{pmatrix}}k[x,y] \rightarrow k[x,y]/(x^i,y^j)\rightarrow 0](https://s0.wp.com/latex.php?latex=%5Cxrightarrow%7B%5Cbegin%7Bpmatrix%7D+x%5Ei+%26+y%5Ej%5Cend%7Bpmatrix%7D%7Dk%5Bx%2Cy%5D+%5Crightarrow+k%5Bx%2Cy%5D%2F%28x%5Ei%2Cy%5Ej%29%5Crightarrow+0&bg=ffffff&fg=666666&s=0&c=20201002)
and turn it into sheaves over
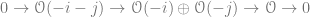 .
.However, it’s at least useful for myself to remember how the machinery below works in a basic example.
________________________________________________________________________________________________
To do so, we first recall the general recipe for how to get a extension from an element of the Ext group. Instead of just recalling the construction, we will derive part of it in a way that I think a beginner could come up with, as I don’t see this written down either. Those who aren’t interested can just skip the next section.
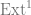 and extensions
and extensions Since projectives are easier for me to think about than injectives, we’ll motivate this by constructing extensions of 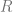

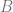

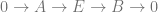 ?
?I know I have had the experience of trying to ask this on mathstackexchange and getting a bunch of answers telling me to learn homological algebra and Ext, which is more effort than a poor undergraduate wants to spend to get at a concrete problem. However, I think there is a natural direct approach.
Instead of 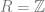
To do so, we can find a surjection 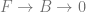

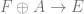

Here, 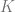
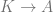

.
Conversely, if we have such a map
The main issue I see with this approach is that it’s not clear to me how to classify that two such maps 
Now, we want to use the section above to construct our extensions. One technical issue is that the quasicoherent sheaves don’t usually have enough projectives, so we would have to work with injective objects instead. The same argument in the previous section works exactly, so, we can fix an injective object 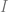
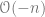
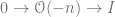
.is a pullback of the diagram

for some map 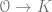
Unfortunately, I don’t know of a good way of writing such an 

The long exact sequence applied to 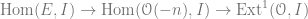

Therefore, instead of using an injective object for 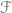
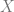
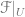
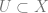
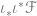
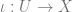
The Cech complex gives us the exact sequence of sheaves
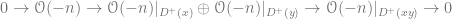 ,
,so we have 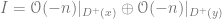

Recall that a basis of 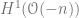

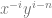
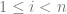
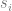
Reading somebody else's computations isn't usually that enlightening, so I'll state the answer first. I got that the rank 2 bundle

from 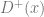
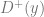
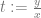

Over 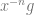
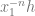


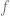
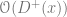
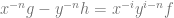
Equivalently, 
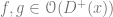
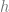
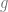
The situation over 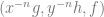
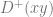
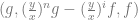
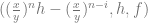
This means the transition matrix is given by 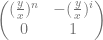
Finally, the identify ![GL_2(k[t])](https://s0.wp.com/latex.php?latex=GL_2%28k%5Bt%5D%29&bg=ffffff&fg=666666&s=0&c=20201002)
![GL_2(k[t^{-1}])](https://s0.wp.com/latex.php?latex=GL_2%28k%5Bt%5E%7B-1%7D%5D%29&bg=ffffff&fg=666666&s=0&c=20201002)
 .
.
.
This means the section
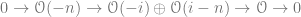
.
Generalized Nonaveraging Integer Sequences January 9, 2015
Posted by Dennis in Uncategorized.2 comments
Everybody who participated in RSI 2009 from this blog have now just finished their undergraduate degrees. I think it’d be interesting to have an update to see how everybody is doing.
I think in the future, I’ll add posts here either to 1) explain intuitively what happens in a paper of mine or 2) write the proof or idea of something that is hard for me to find in the literature. The audience for 1) is going to be really small, considering the lack of papers and people who read them (but I feel sorry for them), and 2) would be to help myself learn.
This time, I’ll try to outline intuitively what went on in my RSI project 5 years ago, the reason being that the main ideas (I think) are pretty well-disguised behind the technical details, which are really just a bunch of casework. The paper is here: http://arxiv.org/pdf/1107.1756.pdf.
As for motivation, we recall that there is the open problem of trying to find the largest subset 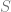
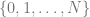

Disregarding the current literature, the most naive way to approach this problem is to use the greedy algorithm. Namely, you start with
It turns out that the greedy algorithm generates a sequence 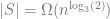
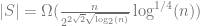
The condition that the sequence has no three term arithmetic progression is equivalent to avoiding (nontrivial) solutions to 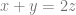
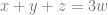
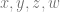
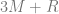
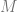
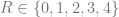
What happens if we consider avoiding solutions to
where all the 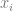
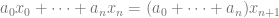
In general, I think we don’t understand this at all (or at least we didn’t understand it 5 years ago). From generating these sequences with a computer, it seems like, if you have a bunch of terms that are close together, then that forces the next terms in the sequence to be farther apart. Similarly, if a bunch of terms are far apart, then the next terms in the sequence are closed together. This makes complete sense heuristically.
I wish I still had the actual graphs to give an idea, but the graph of the sequence would typically be flat at the beginning, suddenly grow because of the terms bunched together. Then, since the terms are spread out, it would suddenly become flat again. This would repeat. Instead of simply cycling, the times where the graph is either flat or growing really fast increases with each iteration. I think they increase geometrically, but it was hard to compute enough terms to see.
In some very special cases, this pattern is so extreme that the part where the graph is growing really fast is instead a perfect jump. This is because the terms in the beginning are so bunched together that there are simply no gaps to stick any more terms. Consider, for example, the graph of the sequence that avoids 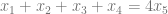

My RSI paper was just to try to find these some of these sequences and their closed forms (for example the one above). The idea is the same as Layman’s paper, where the closed form is 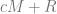

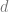
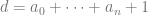
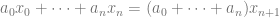
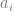
In general, I think it’s interesting to try to find the growth rate of these sequences, but my guess is that it is difficult. In fact, I didn’t found anything in the literature that beats the silly counting argument (other than heuristic arguments) during RSI in terms of an upper bound. It’s messy, yet not random.
Nim-Chomp August 19, 2010
Posted by lumixedia in combinatorics, math, Problem-solving.Tags: combinatorial game theory, combinatorics, rsi
4 comments
Wow, I’m really not cut out for helping to maintain a blog, am I? So what finally prompted me to post was Dr. Khovanova’s description of the game of Nim-Chomp at her blog, which she suggested I respond to.
So Dr. Khovanova described Nim-Chomp to me at RSI more than a year ago, and I thought I solved it. Then a few months ago I found a flaw, thought it was hopeless, and gave up. Then a few minutes ago I realized that the flaw was in fact fixable. The point of this paragraph is that I’m not sure I’m to be trusted regarding this problem, but I’ll try.
I won’t repeat the problem statement here. Too lazy. Just read her post. Because I find it easier to think about this way, I’ll make a slight modification to the Chomp perspective on Nim-Chomp: on a given turn, each player may only eat squares from a single *column* (rather than a single *row*).
First let’s pretend the bottom left square is not actually poisoned. We can transform this easy-Nim-Chomp into regular Nim as follows: for a given position in easy-Nim-Chomp, suppose the number of squares remaining in each column is a1, a2, …, an from left to right. Let b1 = a1 – a2, b2 = a3 – a4, …, b[n/2] = (an-1 – an) or (an) depending on whether n is even or odd. Then this position is equivalent to regular Nim with piles of b1, b2, …, b[n/2]. Basically, we’re splitting the chocolate columns into pairs of adjacent columns and considering the differences between the members of each pair to be the piles of our regular game of Nim. Because the piles are in nonincreasing order, this is a well-defined transformation.
It works as follows: suppose the loser of the Nim-game (b1, b2, …, b[n/2]) eats some squares from the kth column where k is odd. This decreases the value of ak, thereby decreasing one of the Nim-piles as in a regular Nim-game, so the winner just makes the appropriate response. Instead, the loser might try to dodge by eating squares from the kth column where k is even, thus decreasing the value of ak but increasing one of the Nim-piles rather than decreasing it, which can’t be done in regular Nim. But the winner can simply decrease ak-1 by the same amount and leave the loser in the same position as before. There are a finite number of squares, so the loser can’t keep doing this. Eventually they must go back to decreasing piles, and lose.
This is how far I got at RSI. I didn’t realize the poisoned lower-left square was a significant issue, but it is. Thankfully, all it really does (I think) is turn the game into misère Nim rather than normal Nim. We make the transformation to Nim-piles in the same way as before, and the winner uses nearly the same strategy as in the previous paragraph, but they modify it to ensure that the loser is eventually faced with “bk”s which are all 0 or 1 with an odd number of 1s. (Maybe one day if I get around to writing a basic game theory post I’ll explain why this is possible. Or you can check Wikipedia. Or just think about it.) When the loser increases some bk, the winner eats squares in the corresponding column to decrease it back to 0 or 1; when the loser decreases a 1 to a 0, the winner decreases another 1 to a 0.
Eventually, the loser is forced to hand the winner a chocolate bar consisting of pairs of adjacent equal columns. At this point the winner takes a single square from any column for which this is possible, leaving a bunch of 0s with a single 1—i.e. another misère 2nd-player win. This continues until we run out of squares, at which point we conclude that the loser of the new game of misère Nim is indeed the player who consumes the poisoned square in the original game of Nim-Chomp.
Question I’m too lazy to think about right now: can we still do this or something like this if we poison not only the bottom left square of the chocolate bar, but some arbitrary section at the bottom left?
A Puzzle June 25, 2010
Posted by genericme in Uncategorized.6 comments
Consider a set of 


I have yet to find a satisfactory closed-form expression for even 

Is this a well-known problem?
Random updates June 14, 2010
Posted by Akhil Mathew in Uncategorized.2 comments
It’s been another two months already since anyone last posted here, hasn’t it?
So, first of all, Damien Jiang, Anirudha Balasubramanian, and I have each uploaded the papers resulting from our RSI projects to arXiv. I’ve been discussing the story of my project on representation theory and the mathematics around it on my personal blog (see in particular here and here). There are others from the program who have placed their papers on arXiv as well (but are not involved in this blog).
I’d like to congratulate my friend and fellow Rickoid Yale Fan for winning the Young Scientist award at the International Science and Engineering Fair for his project on quantum computation (which deservedly earned him the title “rock star”). I also congratulate his classmate and fellow rock star Kevin Ellis (who did not do RSI, but whom I know from STS) for winning the (again fully deserved) award for his work on parallel computation. There is a press release here.
RSI 2010 is starting in just a few more days. I’m not going to have any involvement in the program myself (other than potentially proofreading drafts of kids’ papers from several hundred miles away), nor do I know much about what kinds of projects (mathematical or otherwise) will be happening there. I think I’d be interested in being a mentor someday—maybe in six years time. I’m going to be doing a project probably on something geometric this summer, but it remains to be seen on what.
I don’t really know what’s going to become of this blog as we all now finish high school and enter college. It looks like most of us will be in Cambridge, MA next year; this is hardly surprising given the RSI program’s location there. Also, just to annoy Yale, I’m going to further spread the word that he is going to Harvard.
If anyone from RSI 2010 wants to join/revive this blog, feel free to send an email to deltaepsilons [at] gmail [dot] com.
Intel day 4 March 14, 2010
Posted by Akhil Mathew in General.Tags: Intel STS
3 comments
I had the last day of judging today at Intel. The 40 finalists first went to the Capitol to take a bunch of pictures, then to the Einstein statue at the NAS for another one. We then went in the project exhibition hall. I met with seven judges, two of who were mathematicians. In order that future generations of Intelists may face the day of judgment without crushing uncertainty in the morning, I shall briefly describe my experience.
The first two judges I had were mathematics judges. The first one asked me what I would do if I were giving a talk about my project at a colloquium. He asked me to explain one of my results, which I initially did incorrectly (having not looked through the older proof in quite some time) but fixed along the way. He asked me how I had learned algebraic geometry (or, more precisely, that rather small subset I can claim to vaguely understand). Interestingly, he referred to a specific result in my paper by number (3.10; I didn’t remember what that was for sure)—one of the differences between Intel and ISEF is that the judges read the papers.
The second mathematician asked me to give an overview of my project in detail, so I went into my usual spiel. She asked me a few questions along the way about how the results were proved. Finally, she asked where I was going to go to college. I said that I didn’t know yet. This was a somewhat longer interview.
There were others who wanted a brief overview and then left. A computer scientist who had asked me earlier about certain algorithms and an engineer that asked about the law of atmospheres chatted with me about extensions of those problems.
The exhibits were then opened to the public. I met a few RSI 2009 alumni from the D.C. area. Most people were not mathematicians, which made explaining my project (on representation theory in complex rank) a somewhat difficult task, though there were some that knew, e.g. group theory. I wasn’t envious of my neighbor Joshua Pfeffer with mobs of people craning to hear about the super Kahler-Ricci flow though owing to me extreme hoarseness despite my consuming two bottles of fluids. Also, my parents stopped by to say hello and see the other projects.
I’m somewhat tired now, and there’s not that much more I really can say about it without going into technical details.
Intel day 3 March 13, 2010
Posted by Akhil Mathew in General.Tags: Intel STS
5 comments
(Today was the third day of the Intel STS competition.)
I had my third judging interview today at about 11:40 am. The judging panel included a computer scientist who pointed to the seven wrapped chocolates on the desk and informed me that to each was assigned a number, and that I needed to discover which contained the median. I didn’t have the actual numbers, but I could compare any two. In the end, I said something about 
I then had lunch and went to the National Academy of Sciences, where we set up our projects. My poster had developed a slight tear from being sent through the mail, but I fixed it with construction paper.
Intel STS: Liveblogging day 2 March 12, 2010
Posted by Akhil Mathew in General.Tags: Intel STS
2 comments
I’m going to try liveblogging (insofar as possible) a science fair. [9:24- It’s now pretty clear that what I’m doing is more like deadblogging. Still, it’s better than nothing, I suppose.]
(9:45) So I’m at the 2010 Intel Science Talent Search in Washington, D.C. Presumably many of the folk that come across this blog will have heard of it; it’s a science competition for high school seniors. There are seven people from RSI here this year. I’ve also met many interesting people among the other finalists for the first time, all of whom seem to be rather beastly. Everybody arrived yesterday–I took the train–but nothing competitive actually happened. Today, we will be judged by a panel of ten or eleven scientists and mathematicians who are going to ask us general questions about science in general, and not our projects. My first interview is in about half an hour, so I’m basically procrastinating by writing this entry, if there was anything that I could do to prepare :-).
In any case, it was pretty cool to find that I’m in a room that has a TV in the bathroom. The hotel is ridiculously fancy.
After this, I’m going to go back to random Wikipedia surfing about diverse scientific topics. They told us this morning that the judges want to see the scientific process rather than technical knowledge–perhaps this is a license for me to babble? I’ve always enjoyed idle pontification. In any case, I promise more later after my judging interview. (more…)
Is early specialization good? March 4, 2010
Posted by Akhil Mathew in General.2 comments
Thomas Sauvaget asked a question on MO on whether specializing early is a good thing. It got into an interesting discussion, which continues on his blog. I have placed some of my own thoughts there, so I won’t ramble here.
In an unrelated note, if you haven’t already seen it, you ought to watch the MAA’s great 
Some unsolved problems January 3, 2010
Posted by Damien Jiang in Problem-solving.Tags: functional equation, geometry, IMO longlist, incircle, integer functional equation, Russian Olympiad
10 comments
Happy New Year!
Since we have been too lazy to post lately (and the so-not-lazy Akhil posts mostly elsewhere now), I’m going to post some problems that I probably should be able to solve, but haven’t.
